at Medium: “…So why, then, does granular, social data make people uncomfortable? Well, ultimately—and at the risk of stating the obvious—it’s because data of this sort brings up issues regarding ethics, privacy, bias, fairness, and inclusion. In turn, these issues make people uncomfortable because, at least as the popular narrative goes, these are new issues that fall outside the expertise of those those aggregating and analyzing big data. But the thing is, these issues aren’t actually new. Sure, they may be new to computer scientists and software engineers, but they’re not new to social scientists.
This is why I think the world of big data and those working in it — ranging from the machine learning researchers developing new analysis tools all the way up to the end-users and decision-makers in government and industry — can learn something from computational social science….
So, if technology companies and government organizations — the biggest players in the big data game — are going to take issues like bias, fairness, and inclusion seriously, they need to hire social scientists — the people with the best training in thinking about important societal issues. Moreover, it’s important that this hiring is done not just in a token, “hire one social scientist for every hundred computer scientists” kind of way, but in a serious, “creating interdisciplinary teams” kind of kind of way.
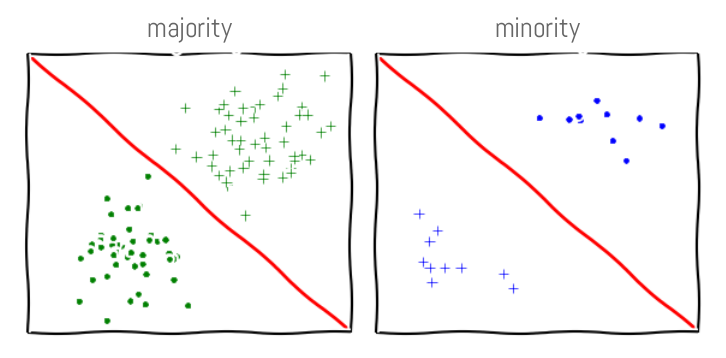
While preparing for my talk, I read an article by Moritz Hardt, entitled “How Big Data is Unfair.” In this article, Moritz notes that even in supposedly large data sets, there is always proportionally less data available about minorities. Moreover, statistical patterns that hold for the majority may be invalid for a given minority group. He gives, as an example, the task of classifying user names as “real” or “fake.” In one culture — comprising the majority of the training data — real names might be short and common, while in another they might be long and unique. As a result, the classic machine learning objective of “good performance on average,” may actually be detrimental to those in the minority group….
As an alternative, I would advocate prioritizing vital social questions over data availability — an approach more common in the social sciences. Moreover, if we’re prioritizing social questions, perhaps we should take this as an opportunity to prioritize those questions explicitly related to minorities and bias, fairness, and inclusion. Of course, putting questions first — especially questions about minorities, for whom there may not be much available data — means that we’ll need to go beyond standard convenience data sets and general-purpose “hammer” methods. Instead we’ll need to think hard about how best to instrument data aggregation and curation mechanisms that, when combined with precise, targeted models and tools, are capable of elucidating fine-grained, hard-to-see patterns….(More).”