Chris Taggart – OpenCorporates, the Largest Open Database of Companies in the World. What, How, and Where Next?
07 April 2014
At the latest GovLab Ideas Lunch, Chris Taggart, Co-Founder and CEO of OpenCorporates, presented his company’s work as a case study of innovating by applying open data to better understand the corporate world.

In order to build awareness of and support for open data, President Obama declared last year that open data “is going to help more entrepreneurs come up with products and services that we haven’t even imagined yet.” In a report released last fall, McKinsey & Company put a price to this promise, estimating that open data may generate over $3 trillion of revenue worldwide. While this estimate is encouraging, many in the private sector remain uncertain of just how much economic value open data can unlock.
Taggart began his talk by describing open data as a driver of creativity, innovation, competition, efficiency and sharing. This assertion about open data forms the basis of OpenCorporates’ work, which involves logging and sharing data on corporate entities in order to build the world’s largest openly licensed database of companies. The information is available through a searchable, sortable API as well as the website and various maps and data visualizations.
The value of sharing and accessing this information lies in the user’s ability to get easy access to statutory information about companies in a wide range of jurisdictions. As its statement of purpose explains, “OpenCorporates exists to make information about companies and the corporate world more accessible, more discoverable and more usable, and thus give citizens, community groups, journalists, other companies, and society as a whole the ability to understand, monitor and regulate them.” It’s now adding corporate relationship data to this data, and has made particularly strong strides, says Taggart, in mapping US banks.
Taggart illustrated the importance of being able to quickly access such a database by describing the Lehman Brothers collapse: “People asked, ‘What’s going to happen if we let Lehman Brothers fold?’ and others said, ‘I have no idea. I have no idea what it is and how it’s linked to other things.’ And when it folded, financial companies around the world wondered what their exposure might be – and the truth was they didn’t know – they didn’t know which deals they had that were with a company in the Lehmans group, or which financial products were in some ways underwritten by a part of Lehmans. From the point of view of credit risk, it’s critical to see know who you’re dealing with and how these companies are linked together.”
Taggart said that while the traditional proprietary databases do have relationship data, the data they have typically has a large number of serious problems:
- Data accuracy – data is often re-coded or “re-keyed” and few individuals review it. In other words, individuals do not face a downside to lying;
- Gaps in data – costs of data entry itself are extremely high and quality control is prioritized first for those paying to access the data;
- Lack of granularity – the proprietary systems typically use legacy software and data models that are hard to reengineer;
- Errors go uncorrected – not enough feedback loops or mechanisms exist to track and correct errors in the data;
- Black box – data providers often cannot reveal their data sources, which limits their usefulness and the trustworthiness of the data; and
- Isolation – many data creators and providers assign proprietary IDs as internal identifiers, which become barriers to sharing and improved data quality.
Getting Hold of the Data
Although OpenCorporates aims “to have a URL for every company in the world,” Taggart explained that multiple barriers exist to accomplishing this seemingly straightforward goal. For example, the data is not always easily available and even when it is there can be challenges in making sense of it and keeping up to date.
OpenCorporates gets its data either from official sources (e.g. official APIs and data dumps) or by ‘scraping’ websites. For example, in the UK – where OpenCorporates uses the official API as it does not add licensing restrictions or charge a fee for the data – they have extremely current data, but if when scraping a website containing, say, 200,000 records, it can take a million seconds to complete (assuming each web-page takes 5 seconds to get). With the US bank data, they had to write code to extract data from 900+ page PDFs.
In the case of corporate relationship data, finding sources for this information is very hard, and when it does exist it’s often in free text that can’t be parsed automatically.
Crowdsourcing
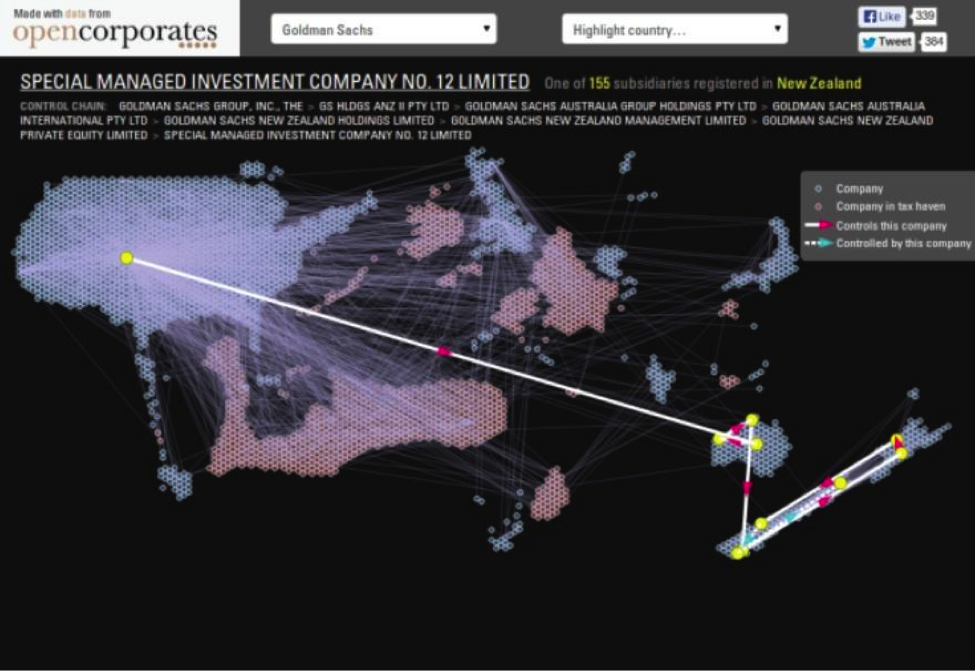
Attempting to fill the aforementioned gaps in data creates another major challenge to mapping complex corporate structures. For example, while the OpenCorporates may have extensive data about Goldman Sachs’ corporate structure, finding information on other companies is much more difficult – even the filings to the Securities & Exchange Commission are problematic, containing only a fraction of the real number of subsidiaries and being described as free text, rather than as data.
OpenCorporates addresses this problem by harnessing the technique of crowdsourcing, thus greatly expanding its knowledge base: “Some people get really into the process. For Disney, we got over 600 connections [to other companies], most done by one person in three days.” Other crowdsourced contributions include “people adding websites, telephone numbers and so on.”
Although crowdsourcing is an extremely effective way to engage a greater community and tap into a larger knowledge base, Taggart acknowledged that crowdsourcing poses its own set of challenges. He elaborated by stating that it’s hard to get the balance between getting high quality data and making it easy to contribute.
Next Steps
Since launching in late 2010, OpenCorporates has grown from 3 million companies in 3 jurisdictions to over 60 million in 80 jurisdictions. While it has already worked with the open data community to build data scrapers, the OpenCorporates team wants to do more.
Taggart ended his talk by announcing his company’s biggest goal to date. Last year, OpenCorporates began adding corporate hierarchy data, tackling the difficult task of combining varied types of ownership and control data from multiple sources, particularly in the financial sector. This year, OpenCorporates began an even bigger challenge: finding, importing and matching the millions of public records, particularly regulatory data, that relate to companies, from bank licenses to health and safety violations. They have already collected over half a million US financial license records, for example.
While it is clear that much of the corporate world still needs time to fully embrace the business opportunity of open data, OpenCorporates is a living example of its potential to generate revenue, foster meaningful connection with other institutions such as government, and engage the greater public.
